Das Dilemma, das viele Unternehmen kennen
Die Mitarbeiter nutzen ChatGPT. Manchmal für harmlose Texte, manchmal für Kundendaten, manchmal für interne Prozessbeschreibungen. Die IT-Abteilung weiß es, toleriert es stillschweigend oder hat es verboten – letzteres ohne messbaren Erfolg.
Das eigentliche Problem ist kein Disziplinproblem. Es ist ein Angebotsproblem: Wenn ein Unternehmen keine sichere, datenschutzkonforme KI-Lösung bereitstellt, suchen Mitarbeiter eigenständig nach Wegen. Shadow AI entsteht nicht aus böser Absicht, sondern aus dem Wunsch nach Produktivität.
Die Lösung lautet: ein unternehmenseigenes, selbst gehostetes LLM, das Mitarbeitern dieselbe Produktivität bietet – ohne Datenschutzrisiko.
Was heute technisch möglich ist
Noch 2023 waren Open-Source-Sprachmodelle lokalen Cloud-Modellen klar unterlegen. Das hat sich geändert. Aktuelle Modelle wie Llama 3.3 (Meta), Mistral (Frankreich) oder Phi-4 (Microsoft) liefern für viele Unternehmensanwendungen – Textzusammenfassung, Dokumentenanalyse, interne Wissensabfragen, Code-Assistenz – Ergebnisse, die kommerziellen Cloud-Modellen der vorherigen Generation kaum nachstehen.
Fast 90 % der Unternehmen, die KI einsetzen, integrieren laut Linux Foundation bereits Open-Source-Technologien. Der Trend ist eindeutig: Hybride Architekturen setzen sich durch – lokale Modelle für 80 % der Standardaufgaben, Cloud-Modelle nur noch punktuell für komplexe Reasoning-Aufgaben.
Der DSGVO-Vorteil ist real
Beim Einsatz von CloudLLMs wie ChatGPT (OpenAI/Microsoft Azure) oder Gemini (Google) landen Eingaben auf US-amerikanischen Servern. Auch wenn beide Anbieter mittlerweile EU-Rechenzentren betreiben und DSGVO-konforme Enterprise-Verträge anbieten, bleibt ein strukturelles Problem: Das Unternehmen gibt die Kontrolle über Datenwege ab und muss darauf vertrauen, dass Vertragsklauseln eingehalten werden.
Bei einem selbst gehosteten LLM verlässt keine Eingabe die eigene Infrastruktur. Personenbezogene Daten, Konstruktionspläne, Vertragsdetails oder Kundendaten bleiben im eigenen Rechenzentrum oder der eigenen Cloud-Instanz. Das ist keine Frage des Vertrauens, sondern der technischen Kontrolle.
Besonders in Deutschland, wo 53 % der KI-abstinenten Unternehmen Datenschutzbedenken als Hauptgrund nennen, ist das ein entscheidender Hebel zur Adoption.
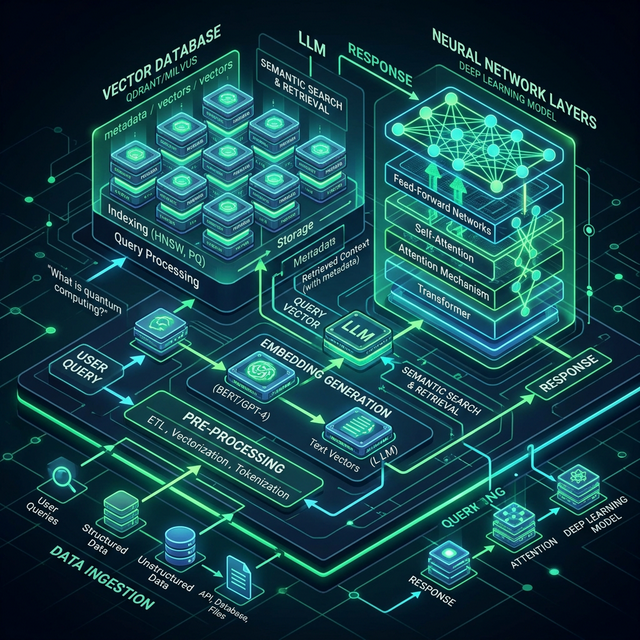
RAG: Wie das Modell Ihr Unternehmenswissen kennt
Ein allgemeines LLM kennt Ihr Unternehmen nicht. Es kennt keine internen Prozesse, keine Produktspezifikationen, keine Kundendaten. Hier setzt Retrieval-Augmented Generation (RAG) an: Das Modell wird mit einer Wissensdatenbank verbunden – Sharepoint-Dokumente, Wikis, technische Handbücher, PDFs – und ruft relevante Inhalte dynamisch ab, bevor es antwortet.
Das Ergebnis: ein interner KI-Assistent, der Fragen zu Ihren eigenen Prozessen, Produkten und Verfahren beantwortet – ohne dass die Daten dafür in ein externes Modell eintrainiert werden müssen. Daten bleiben Daten, das Modell bleibt das Modell.
Der Technologie-Stack, der sich bewährt hat
Für mittelständische Unternehmen hat sich folgende Architektur als praktikabel erwiesen:
- Ollama als lokale Modell-Laufzeitumgebung: Einfaches Deployment verschiedener Open-Source-Modelle auf eigener Hardware oder in eigenen Cloud-Instanzen.
- AnythingLLM oder Open WebUI als Benutzeroberfläche: Chat-Interface für Mitarbeiter, Dokumentenintegration, Gesprächshistorie – ohne technische Vorkenntnisse bedienbar.
- Mistral 7B oder Llama 3.1 8B für Standardaufgaben: Auf einer modernen Server-GPU ausführbar, die meisten Bürotätigkeiten abdeckend.
- Vektordatenbank (z.B. ChromaDB oder Qdrant) für RAG: Speichert semantisch durchsuchbare Repräsentationen Ihrer Dokumente.
Das klingt komplex, lässt sich aber mit vorhandener IT-Infrastruktur in wenigen Wochen aufbauen – und danach wartungsarm betreiben.
Was zu beachten ist
Ein selbst gehostetes LLM ist kein Allheilmittel. Drei Punkte verdienen besondere Aufmerksamkeit:
- Betriebsvereinbarung: KI-Assistenten im Arbeitsumfeld berühren Mitarbeiterrechte. Eine klare Betriebsvereinbarung, was das System protokolliert und wie es eingesetzt wird, ist vor dem Ausrollen Pflicht.
- Modellauswahl und Updates: Open-Source-Modelle müssen aktiv gepflegt werden. Sicherheitslücken in Modell-Frameworks (wie Ollama) müssen zeitnah gepatcht werden.
- Halluzinationen bleiben ein Thema: Auch lokale Modelle erfinden gelegentlich Fakten. RAG reduziert das Problem erheblich, eliminiert es aber nicht vollständig. Mitarbeiter müssen das verstehen und Ausgaben kritisch prüfen.
Mein Fazit
Wer als Unternehmen KI einsetzen will, ohne Betriebsgeheimnisse an Cloud-Anbieter zu übergeben, hat heute ernsthafte Alternativen. Selbst gehostete LLMs sind 2026 kein Kompromiss mehr – sie sind eine bewusste strategische Entscheidung für Datensouveränität, Kostenkontrolle und unabhängige KI-Kompetenz im eigenen Haus.
Wenn Sie wissen möchten, welche Architektur zu Ihrer Infrastruktur passt, sprechen Sie uns an. Der Aufbau eines unternehmenseigenen KI-Stacks ist einer unserer Schwerpunkte.