Die Blackbox öffnen: Über reine API-Aufrufe hinaus
Für viele Entscheider, aber auch für Senior-Entwickler aus klassischen objektorientierten Systemwelten, ist Künstliche Intelligenz zunächst eine undurchschaubare Blackbox. Die Annahme "Wir rufen einfach die OpenAI-API auf und haben KI im Unternehmen" führt zu fragilen, fehleranfälligen Applikationen. Um robuste, skalierbare und vor allem datenschutzkonforme Applikationen für den Enterprise-Sektor zu bauen, muss die zugrundeliegende Architektur verstanden und orchestriert werden.
Das Fundament: Embeddings und der Vektorraum
KI-Modelle verstehen keine Sprache, sie verarbeiten ausschließlich Matrizen und Tensoren. Der allererste Schritt jedes modernen Language-Processing-Systems ist es, semantische Bedeutung in Zahlenreihen zu übersetzen. Dieser Vorgang nennt sich Embedding.
Stellen Sie sich einen multidimensionalen Raum vor. Wörter, die thematisch ähnlich sind, werden in diesem Raum nahe beieinander platziert. Ein Embedding-Modell (wie z.B. text-embedding-3-large) nutzt dafür nicht nur 3, sondern oft 1.536 bis 3.072 Dimensionen. Wenn ein Benutzer nach "Serverausfall" sucht, berechnet das System die Position dieses Wortes im Vektorraum. Datenbankeinträge, die von "Netzwerkunterbrechung" handeln, liegen mathematisch extrem nah an dieser Position – auch wenn kein einziges Wort der Suchanfrage im Zieldokument vorkommt. Die Nähe wird meist mit der Cosine Similarity berechnet. Dies ist die mathematische Magie hinter moderner Such-Infrastruktur.
Das Problem mit Fine-Tuning
Wenn Unternehmen wollen, dass ChatGPT ihre unternehmensinternen Firmenrichtlinien, Produktkataloge oder Verträge "kennt", wird fast immer sofort nach Fine-Tuning verlangt (also das Basismodell mit eigenen Dokumenten weiterzutrainieren). Aus Enterprise-Architektur-Sicht ist das oft ein gravierender Fehler:
- Kosten und Rechenzeit: Fine-Tuning erfordert massiv GPU-Ressourcen. Es ist langsam und teuer.
- Veraltete Daten: Wenn sich morgen ein ISO-Standard oder eine Urlaubsrichtlinie ändert, weiß das trainierte Modell davon nichts. Sie müssten theoretisch täglich neu trainieren.
- Das IAM-Problem (Roles & Permissions): Das größte Problem ist die Sicherheit. Eine KI, die Unterlagen verinnerlicht hat, kann nicht mehr zwischen Berechtigungen unterscheiden. Ein Praktikant erhält unter Umständen Antworten basierend auf den Gehaltsdaten der Geschäftsführung, da das Modell nun mit allem Wissen untrennbar "verschmolzen" ist.
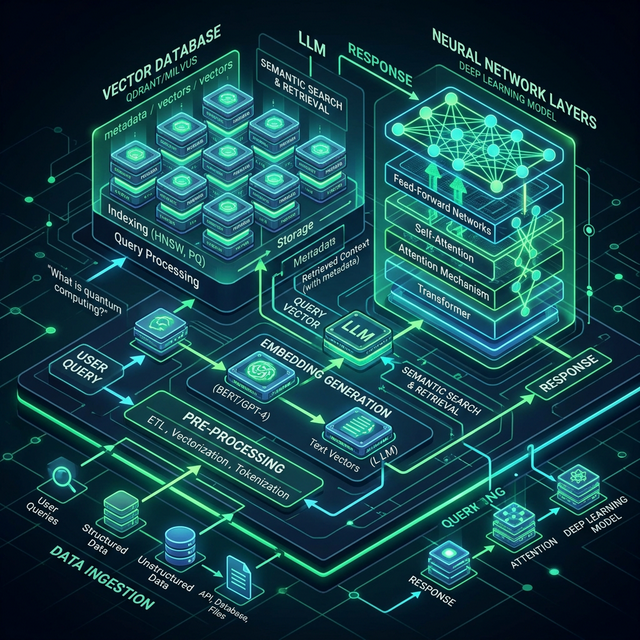
Der Enterprise Standard 2026: Retrieval-Augmented Generation (RAG)
RAG (Retrieval-Augmented Generation) löst die Probleme des Fine-Tunings extrem elegant. Anstatt dem Modell mühsam neues Wissen "beizubringen", operiert das Basis-Modell völlig dumm und generisch. Es erhält das zutreffende Wissen erst in der Millisekunde der Anfrage dynamisch injiziert. Die Architektur gliedert sich in zwei getrennte Phasen:
Phase 1: Ingestion (Datenaufbereitung)
Alle internen Dokumente (PDFs, Confluence-Seiten, Jira-Tickets) werden geladen, automatisch geparst und in Textblöcke (Chunks) von z.B. 512 Tokens zerlegt. Jeder Chunk wird durch ein Embedding-Modell in einen Vektor umgewandelt. Parallel zur Vektor-Repräsentation speichern wir die Metadaten (Dokument-ID, Autor, Zugriffsrechte). All das landet in einer spezialisierten Vektordatenbank (z.B. Qdrant, Milvus, Pinecone oder pgvector).
Phase 2: Retrieval & Generation (Die Nutzeranfrage)
- Ein Nutzer (z.B. aus der IT-Abteilung) fragt: "Wie lautet unser Passwort-Standard für Datenbanken?".
- Das System prüft zunächst die Active Directory Rollen des Nutzers.
- Die Frage wird ebenfalls sofort in einen Vektor umgewandelt.
- Die intelligente Suche: Die Vektordatenbank führt eine mathematische Nachbarschaftssuche durch und extrahiert exakt jene 5 Dokumenten-Chunks, die relevant sind und für die der Nutzer berechtigt ist.
- Die Generierung: Erst jetzt wird das teure LLM aufgerufen. Wir bauen im Code dynamisch einen finalen Prompt: "Du bist ein Assistent. Beantworte die Frage des Nutzers AUSSCHLIESSLICH basierend auf folgendem Kontext: [Die 5 gefundenen Chunks als reiner Textblock eingefügt]. Frage: Wie lautet der Passwort-Standard?"
Dadurch halluziniert das Modell kaum noch, da es strikte Fakten vorliegen hat. Ein unschätzbarer Vorteil für Compliance: Wir können dem Nutzer exakt die Quellen (z.B. "ISMS-Richtlinie Seite 4") unter der Antwort ausgeben, da wir wissen, aus welchem Chunk die Information stammte.
Technologie-Stack & Next Steps für Entwickler
Für moderne DevOps-Teams, die in das Thema einsteigen, empfehlen wir heute keinen Monolithen, sondern hochmodulare Systeme:
- Orchestrierung: LlamaIndex oder LangChain (in TypeScript oder Python) zur Verbindung der Komponenten.
- Lokale Entwicklung & Datenschutz: Ollama, um Modelle wie Llama 3 oder Mistral komplett lokal auf On-Premise-Servern laufen zu lassen. Keine Daten verlassen das RZ.
- Datenspeicher: PostgreSQL mit der
pgvectorExtension. Vermeidet die Einführung eines komplett neuen Datenbank-Systems und erlaubt die Kombination von SQL-Relationalen Daten und Vektor-Suchen in einem Query.
Ein Enterprise-Tipp zum Abschluss: Starten Sie nicht mit dem Versuch, das gesamte Confluence des Konzerns zu indexieren. Beginnen Sie hochspezialisiert – zum Beispiel mit einem Chatbot, der exakt 10 klar definierte Entwickler-Guidelines kennt. Skalieren Sie erst, wenn die Chunking- und Retrieval-Performance für diesen kleinen Datensatz optimiert wurde.